
We aren’t really “mad scientists” here at Derby City Daily.
But (in all humbleness) we’re pretty good inventors.
Take Twitter.
We’re talking about one of the most powerful social networks in the world, used by more than 325 million users on a monthly basis.
And that’s how most folks see it.
We saw more – much more.
We saw Twitter as a pathway to profits – to wealth. And we knew there were road signs pointing the way.
So we put our inventiveness to work to unlock that amazing potential.
We’re a “preferred partner” in Twitter’s ecosystem – a position that gives us direct, real-time access to the firehose of data that gets created every minute of every day.
And we used that special position – and our expertise in a data science known as analytics – to create a trading machine that can supercharge your wealth. Those are the opportunities we bring you here in Derby City Daily.
Our machine sifts through millions of social media posts per day. But, unlike most data scientists, we put a human face on the numbers.
We understand that the consumer is a powerful force when it comes to spending and investing. So we isolate Twitter posts that focus on products, services, brands, and companies that touch consumers’ lives.
We see their posts. Their posted images. Their excitement. And we see how they “vote” with their wallets… on cool new products, fashion, food, beverages, and more. We can hear their stories. We can “listen in” on their conversations. And we get critical insights – direct from the group that matters most.
It’s a huge advantage. We spot powerful trends among Main Street consumers – long before the Wall Street pros see and position trades of their own.
In order to make consumer insights valuable to companies and investors, we need to carefully curate and nurture data.
With such a massive data set to work with (more than 500 million tweets a day) we have a HUGE base to sift through to create value.
How do we do it?
Take a peek into our research lab today and we’ll show you…
How It Works
We built our system specifically to maximize the signals we can get from Twitter data – while protecting user privacy and ensuring data reliability.
Here’s what that means:
- Our relationship with Twitter gives LikeFolio full access to historical data from the social-media firm – as well as real-time feeds. This lets us keep our promise that every company we cover will have full and accurate historical data all the way back to Jan. 1, 2012.
- Unlike other alternate data providers, we don’t rely on shady and inconsistent web-scraping. We get tweets directly from the source in real time, ensuring that our data is clean, accurate, and uninterrupted.
- And because LikeFolio only receives tweets that Twitter users intentionally publish for public consumption; we don’t engage in data-collection tactics that would violate the privacy expectations of the user.
How We Discover/Confirm Brand Product Keywords
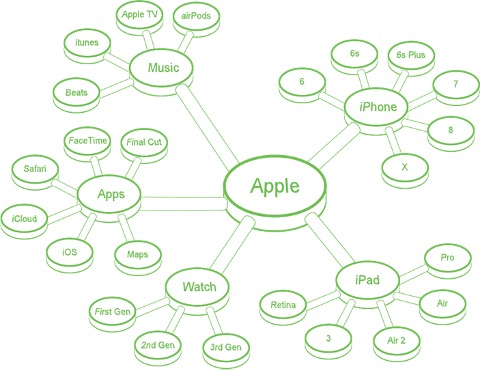
Step No. 1: Use Shrewd Search Strategies
Data scientists refer to it as “discoverability testing.” That’s a heavyweight term for “finding the stuff you’re looking for – as quickly as possible.” Here’s why that’s relevant here.
After all brands and products are identified, we dive into Twitter. Scanning tweets for mentions of “Facebook” is a piece of cake. Quickly spotting mentions of “Apple” is a different ballgame. A query for “Apple” will reveal tweets about the company, the fruit, the childhood board game, and plenty of colloquialisms.
Insider tip: For data to have value about Apple (the company), we need to isolate mentions of its brands, products, and services. This requires a mix of custom keywords and Boolean logic – a strategy that narrows our search and gets results faster.
Step No. 2: Search Like Regular Folks Speak
In data-science lexicon, it’s called “natural-human-language application.” Translated into plain English, we’re really asking: “How do consumers talk about brands and products?” Not necessarily how are they supposed to speak about products (“Apple Watch Series 4”). But how they really say those things (“closed my rings”).
Insider tip: Not all consumers are experts in grammar, spelling, or formal product names. We search Twitter, use real talk, and create thousands of custom keywords to build the largest and most accurate sample size possible for each brand and product within a company.
Step No. 3: Keep Testing the Data
After we’ve identified all potential custom phrases for a company, we test them again with extensive tweet samples and human analysis. Really, our human team reads THOUSANDS of tweets. And we refine everything we do.
Insider tip: We never “stand pat.” We tweak our own logic to refine our data sample when warranted – and eliminate any non-consumer and non-brand-related activity.
Step No. 4: Filter the Noise
Once initial data is aggregated, we review tweets on high-volume dates. And we do this for a reason – to guarantee something called “data integrity.” You see, we annotate each of these dates on our research dashboard to explain the spike. And we make “corrections” on the dates where the catalyst may be media, marketing, or politically related.
Insider tip: We allow our research dashboard users to turn these corrections on and off – instead of eliminating these mentions entirely – because we know the conversations can still be relevant indicators for a company.
Step No. 5: Repeat
When our data gets a final stamp of approval, it doesn’t stop growing. We are constantly scanning for shifts in how consumers discuss brands and products, and we track all new product releases.
Insider tip: We update each company on a regular basis (bimonthly) to keep our data up to speed and predictive.
Comparing Apples to Apples (See what I did there?)
Our methods deliver accurate results. But, like anything in life, there’s a tradeoff.
Our approach sometimes results in a smaller sample size for companies with brands and products that aren’t easily discoverable versus companies with brands and products that have unique (and easy-to-discover) names.
So, a company’s raw mention volume should only be compared against itself – that’s where the relevant trend/change is revealed.
For comparisons between brands/products, we suggest looking at rates of change in each data set to see which companies/brands/products are gaining (or losing) the most traction with consumers.
But this is a definite instance where “less is more.”
We know our data is accurate, and we have the proof to back it up.
And you – our Derby City Daily and LikeFolio followers – are the beneficiaries.
Want an example? Check out the windfall we delivered with Crocs (CROX) – a windfall that surprised the market, but not our followers.
Making our timely call even more remarkable: This is a company that had been the object of ridicule for decades. Yet we spotted the exact right moment to turn bullish.
The company’s footwear – with its “ironically” ugly design, undeniable comfort, and high potential for customization experienced a consumer renaissance so powerful that it launched CROX shares from $20 each to $160 in just two years.
Our real-time analysis of consumer social media activity allowed us to spot this spiking enthusiasm long before the big money investment pros. And that gave our members a shot at gains as high as 1,114% – the definition of a meteoric run.

The proof isn’t in the pudding – it’s in the profits.
Looking to ride the “Next CROX” opportunity? Don’t worry – we’ve got you covered. Check out our top three contenders right here.
All the best,
Megan Brantley
VP of Research